【gizmodo】
ChatGPTリリースから、まだ1年経ってないよね…?
OpenAIが、ChatGPTでの音声・画像認識機能提供を発表しました。つまりChatGPTに画像を送ってその中身を見てもらったり、それに関連する欲しい情報をもらったりできるってことなんです。さらには合成音声のChatGPTと会話したり、音声からテキスト、テキストから音声への変換も可能になるようです。
画像を理解して質問に答えてくれる
ChatGPTでの音声・画像認識について、OpenAIはリリースのページ上でプロモーション動画を公開してます。
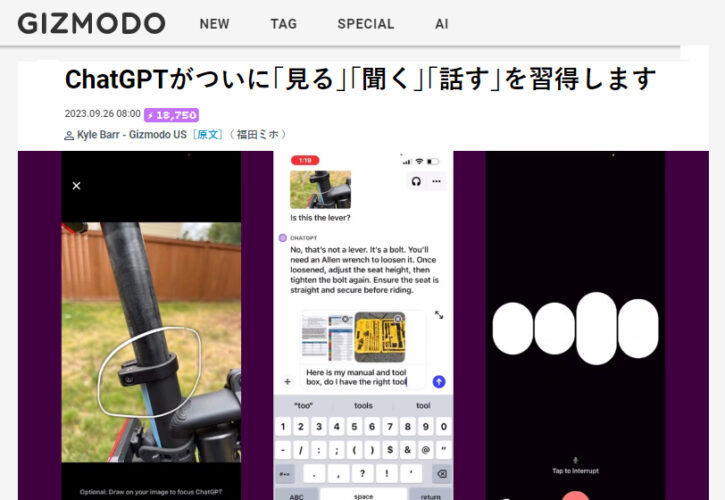
動画では、ユーザーがChatGPTに自転車のサドル調節の仕方を聞いてます。自転車サドル調節初心者と見られるユーザーは、サドルの下のパーツ部分を丸で囲んだ画像をChatGPTに投げ、さらに詳しいアドバイスを求めます。
するとChatGPTは、丸の中のボルトの型を認識し、六角レンチが必要だと教えます。ChatGPTは、マニュアルの画像を認識したり、工具箱の画像を見てそこから適切なサイズのレンチを見つけたりもできるようです。
この機能は、ChatGPT PlusかChatGPT Enterpriseサービスを使っている人限定で提供されます。
今後iOSとAndroidでは、2週間以内に提供開始され、Webバージョンでも近々、画像認識機能が使えるようになるとのこと。
ChatGPTと会話できる

また、合成音声のChatGPTと会話をすることもできます。OpenAIが公開したプロモーション動画では、母親と見られる女性がChatGPTに子供向けの読み聞かせ的なことを頼んでますが、使い道はもっと無数にありそうです。
OpenAIの発表ページには、同一のテキストをいくつかの声色で聞けるサンプルもありました。OpenAIによれば、音声そのものは独自に作ったものではなく、声をライセンス供与した声優さんの声を元にしているとのことです。
OpenAIいわく、彼らの音声合成サービスはChatGPTでの音声チャットで使うだけでなく、Spotifyへのライセンス提供もするそうです。Spotifyも同日にポッドキャストの音声翻訳機能のパイロット提供を発表しました。メジャーなポッドキャストのいくつかのエピソードが、ポッドキャスト主の声はそのままに、英語からスペイン語、フランス語、ドイツ語に翻訳したものが聞けます。
倫理や精度の課題は引き続き
ただ音声合成といえば、ElevenLabsのように嫌がらせに使われてしまったサービスもあり、ChatGPTでもまた心配のタネになりそうです。
また画像入力に関しても、ChatGPTがユーザーのプロンプトを誤解して、珍回答が出てきてしまう可能性があります。OpenAIいわく、リスク回避には専用チームを設けて取り組んだとのことですが、これからいろんなユーザーがきわどい画像での会話を試みてくるのは時間の問題です。
またこのシステムは多分、プロモーション動画ほど高速で高精度ではないと思われます。このChatGPT新機能のプレリリースバージョンを使ってみたWiredによれば、音声認識には数秒かかり、画像認識では人間を認識しないと言ってました。写真に写った人のプライバシー保護がどうなっているのかも、今後精査する必要がありそうです。
OpenAIは米Gizmodoの取材に対し、新機能のリリースは「改善とリスク回避の精緻化のために、時間をかけて徐々に行なっていく」ことが、音声・画像認識においてはとくに重要だと言っています。
ひしめく生成AIたち
2022年11月に立ち上がったChatGPTは、最初こそユーザーが殺到しましたが、近頃は失速しています。OpenAIがChatGPTの能力を制限しているように感じる人も多く、OpenAIとしても、リスク回避と高性能のバランスの取り方に迷いがあるのかな?と見えます。
OpenAIはまた、MetaやGoogle、Anthropicといった他社との競争にも直面しています。
GoogleはGPT-4の競合である「Gemini」をリリースする予定で、そこには画像認識も音声認識も含まれているようです。OpenAIは先週AI画像生成のDALL-E 3を発表し、それはChatGPTとも統合されていますが、まだ取って付けた感があります。
とはいえ、今後それぞれに精度を高めていけば、今回OpenAIが動画で見せたような、その筋の専門家と音と画像で会話できるような状態があちこちで可能になる…のでしょうか? 期待です。
Source: OpenAI