【ascii】
2024年03月18日
アップルの研究チームは3月14日、画像とテキストを理解し処理する能力を持つマルチモーダル大規模言語モデル「MM1」を発表した。今のところ論文のみの公開で、一般公開の時期は明かされていない。
一部ベンチマークではGPT-4Vをも凌ぐ性能を発揮
複数(30億、70億、300億)のパラメータサイズを備えるMM1は、10億以上の画像および30兆語以上のテキスト、GitHubのコード例などの多様なデータセットを用い、教師なし学習と教師あり学習を組み合わせる独自の方法で学習され、多様なタスクに対して高い精度を示すという。
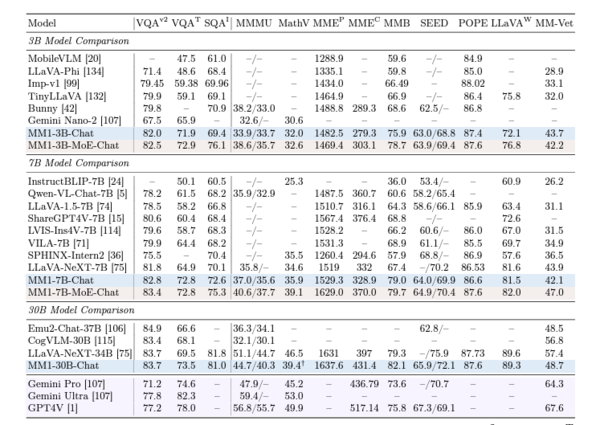
各種ベンチマークの結果によると、30億および70億パラメーターのモデルはそれぞれのモデルサイズにおいて過去最高を記録。特にVQAv2(画像理解)、TextVQA(画像内のテキスト情報)、ScienceQA(科学知識)、MMBench(マルチモーダル)、MathVista(数学)などのベンチマークで強力なパフォーマンスを示している。
また、両モデルはMoE(Mixture-of-Experts:複数の専門家モデルを組み合わせ、効率的に処理ができるアーキテクチャ)モデルも試されており、いずれも通常のモデルよりも優れた性能を発揮している。
さらに、300億パラメーターモデルでは、VQAv2(画像理解)ベンチマークにおいてグーグルの「Gemini Pro」「Gemini Ultra」、そしてOpenAIの「GPT-4V」に勝るスコアを示している。
画像を理解する能力は圧倒的
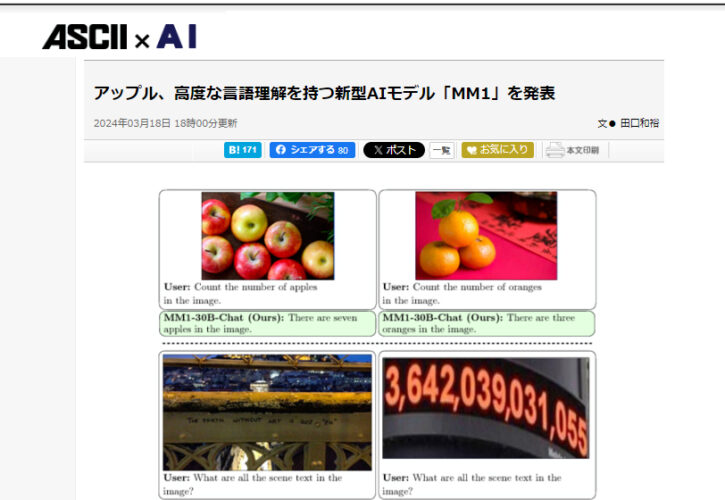
いくつか公開されているデモ画像を見てみよう。

画像内のリンゴやみかんの個数を正確に計測している。

画像内の文字や数字も認識しているようだ。

「画像を見た人間がどのように感じ、反応するか」を問う抽象的な質問にも長文で回答している。

ビーチパラソルの画像から温暖な気候を読み取り、25〜30度の気温を推定したり、雪の上を飛ぶ飛行機の画像から-20〜-30度を推測するなど、画像のコンテキストを理解した対応も得意なようだ。

さらに「画像を使い、先生になったつもりで蒸発と蒸発散の違いを説明する」「フローチャートを説明する」といった難問にも完璧に答えているように見える。
「レシピ」の公開が示すもの
アップルは論文内で、マルチモーダルLLM(MLLMs)は増えているが、その訓練データ、アーキテクチャー、トレーニングの詳細についてはほとんどまたは全く公開されていないことを指摘。
MM1はすべてのコンポーネントに関して、そのアーキテクチャーから、データセットの内容、事前学習・ファインチューニングの詳細、モデルサイズに至るまで、詳細な情報(MLLMsの開発レシピ)を公開している。
アップルが開発レシピを公開したことは、AI研究における透明性と共有を促進する意図を示していると共に、「オープン」をうたいながらクローズドの方向に向かっている競合ビッグテック達に対する一種の牽制とも受け取れる。
近年、グーグルやメタ、マイクロソフト(OpenAI)などは、AIに多大な投資をしているが、その多くは自社のエコシステム内に閉じたものになりがちだ。
アップルはMM1の開発手法を公開することで、AI研究コミュニティ全体の発展に貢献しようとする姿勢をアピールしている。
また、アップルは今年、AIシステムを小型化し効率化する技術を開発するカナダのAI企業「DarwinAI」を買収している。遅れを取ったAI分野でも存在感を高めようとしていることを明確に示している。