これまで多くあるプログラミングの中でもオープンな開発形態と機能をもった場合、他と比較して独自の発展をしやすいことから、ほかのモデルと比較してどういった発展をみせるのかに注目していきたいと思います。(N)2024.3.25
アップルの研究チームは、このモデルの開発において、そのアーキテクチャ、データセットの内容、事前学習・ファインチューニングの詳細に至るまで、従来公開されてこなかった詳細な情報を公開している。これは、AI研究における透明性と共有を促進する意図を示しており、競合他社が進めるクローズドな方針とは一線を画している。
【ledge】
2024/3/22
画像の出典:Dall-E3により ledge.ai が生成
2024年3月14日、アップルの研究チームは、画像とテキストの両方を処理できる能力を持つマルチモーダル大規模言語モデル「MM1」を発表した。
このモデルは画像とテキストの両方を理解し、処理する能力を持つマルチモーダルAIで、一部のベンチマークではOpenAIのGPT-4Vを上回る性能を示している。論文によると、MM1は30億、70億、300億という複数のパラメータサイズを持ち、10億以上の画像および30兆語以上のテキスト、GitHubのコード例など多岐にわたるデータセットを用いた独自の学習方法で訓練されている 。 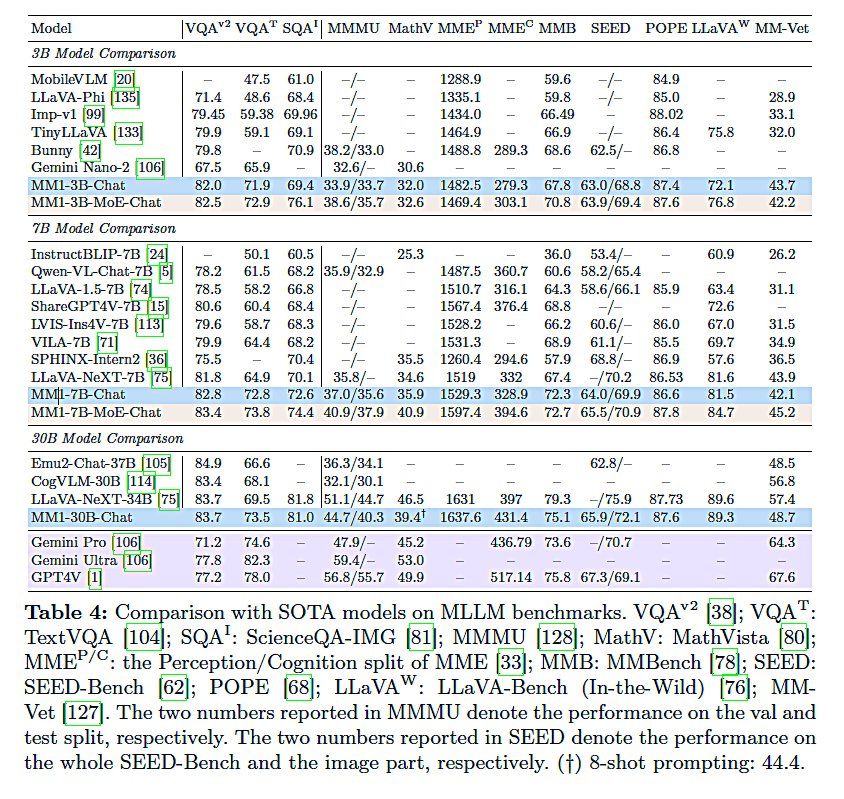
MM1は、画像内のオブジェクトの数を正確に数える、画像内の文字や数字を認識する、画像を見た人間の感じ方に基づく抽象的な質問に長文で回答するといった、画像を理解する能力において特に優れている。 
さらに、ビーチパラソルの画像から温暖な気候を読み取る、飛行機が雪の上を飛んでいる画像から気温を推測するなど、画像のコンテキストを理解した対応も得意としている。これらの能力により、MM1は教育的なシナリオや複雑な問いに答えるなど、様々なタスクで高いパフォーマンスを発揮する 。

アップルの研究チームは、このモデルの開発において、そのアーキテクチャ、データセットの内容、事前学習・ファインチューニングの詳細に至るまで、従来公開されてこなかった詳細な情報を公開している。これは、AI研究における透明性と共有を促進する意図を示しており、競合他社が進めるクローズドな方針とは一線を画している。